记录一个K8S的小坑
-
大假回来,发现一个测试环境的K8S集群起来不了了,作为“踩坑”老手,熟练登录系统并sudo,想无非不过是服务没起来,估计又是swap啥的,但一看命令输出就感到不妙:
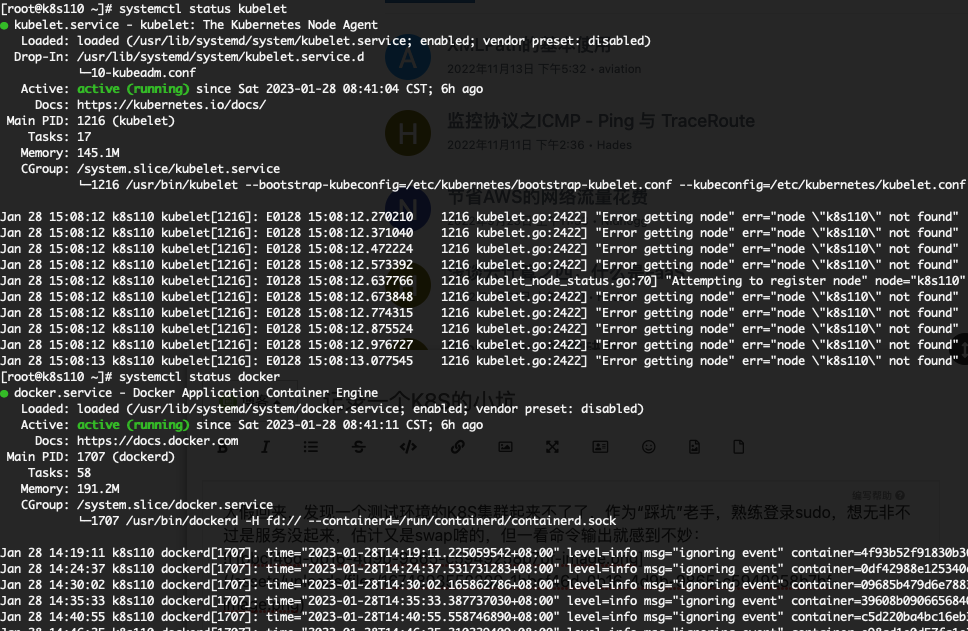
kubectl的报错表明6443没有起来,kubelet服务正常,docker服务也没问题!这倒是第一次碰到,只有硬着头皮看日志了,但日志里面除了说6443端口不可用外,并没有什么有价值的信息。想起自己还是谷歌程序员,但情急之下,没有好的关键字,一通搜索下来也没有看到什么有价值的文章!
还是先试试重启大法吧,于是用systemctl 重启kubelet服务:
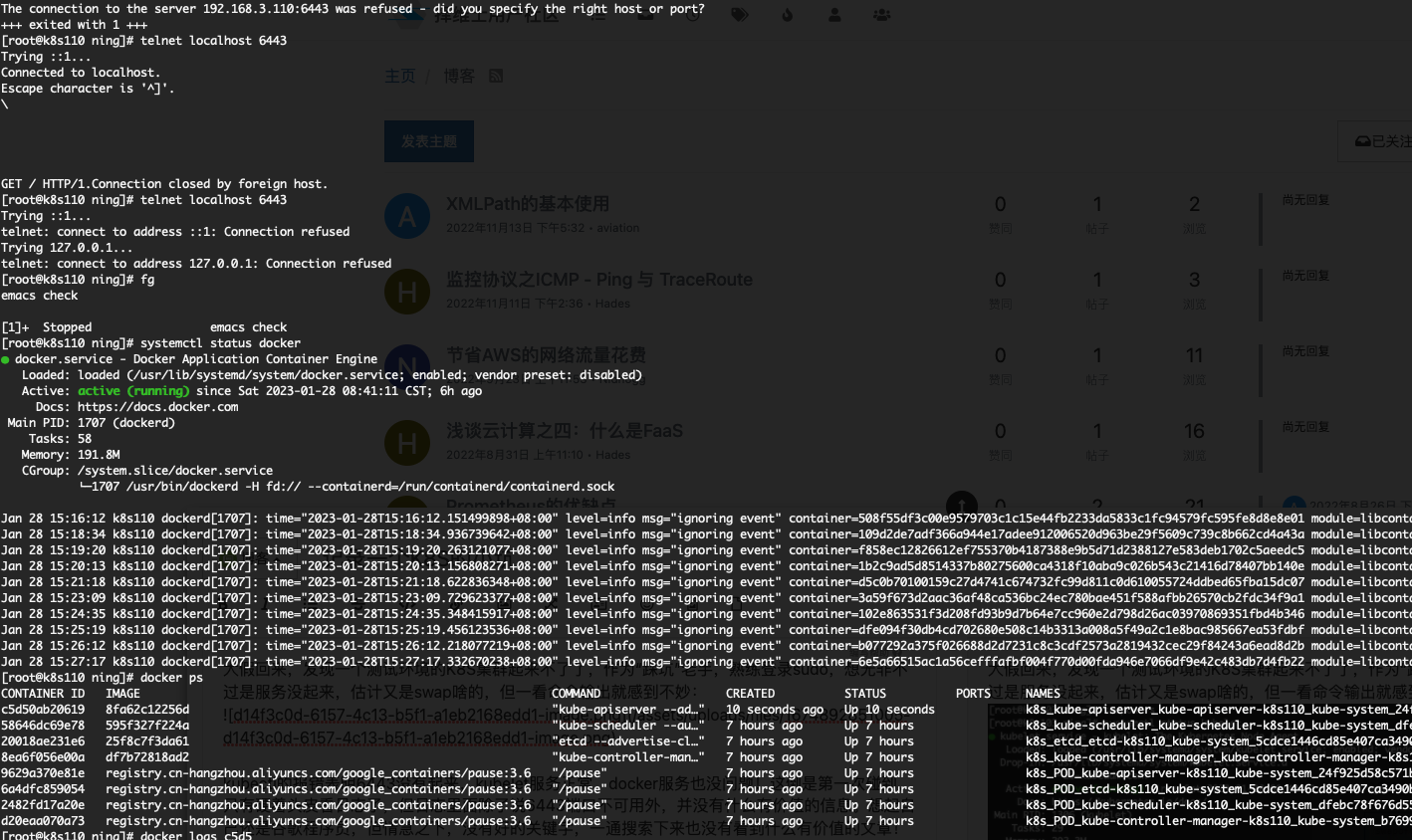
神奇的发现重启后6443 可以了,正在高兴之际发现它只坚持了一小会!心中一万零一只神兽飚过。。。
但突然发现,上面的docker ps的结果中只有api-server被重启过了(上图中显示启动时间10s),这个就神奇了,难道之前api-server的container不存在?否则kubelet 服务重启不会尝试重新启动这些container!!
连忙看看丫的日志里面怎么说的:
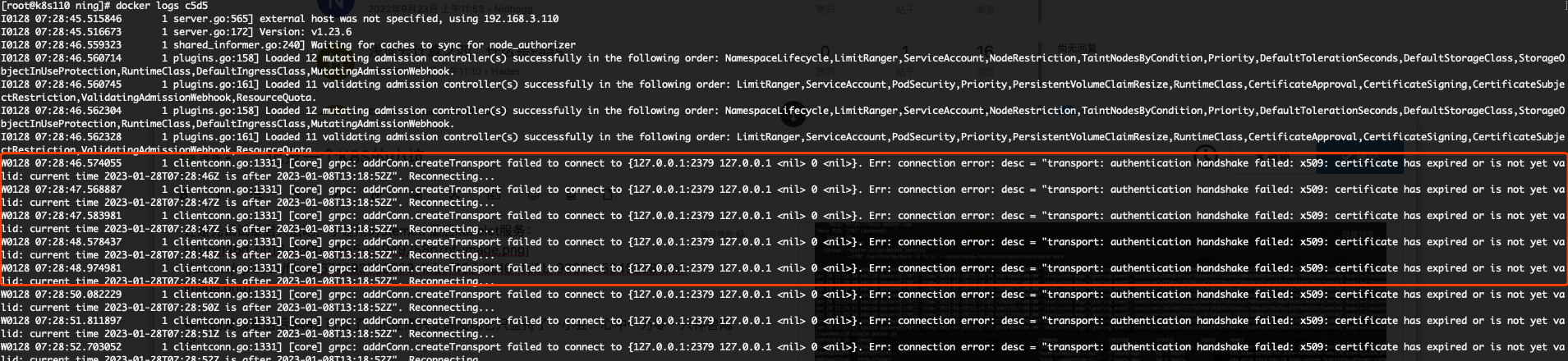
原来如此!我们测试环境的证书该折腾折腾了。。。通过kubeadm certs check-expiration / kubeadm certs renew all 一通命令猛操作下来,再用一把重启大法,集群总算恢复正常了~
又可以放心的喝茶上网摸鱼了
